纽劢研习社 | 视觉SLAM定位二三事
发布时间:2020-09-28写在前面的话:
在纽劢科技,研发一线的工程师们会追踪自动驾驶的前沿技术,并结合开发和应用中的思考实践,定期在内部进行分享。每一次这样的交流,都是一场知识的碰撞和思路的拓展,所以我们用「纽劢研习社」将这些精彩的分享记录下来。欢迎你来这儿与我们交流和碰撞,一起擦出意想不到的知识“火花”~
本期话题:视觉SLAM定位。内容要点:
1. Why visual localization
2. 传统视觉定位的思考
3. 非深度学习方法的应用
4. 深度学习方法的应用:Feature Points,Detection,Semantic Segmentation
01 Why Visual Localization?
高精度定位模块是自动驾驶中重要的组成部分,它的实现方法和涉及的传感器方案有很多,对应的优缺点也各不相同。而利用车载摄像头实现的视觉定位,无疑是未来不可或缺的一种。
依靠视觉进行高精度定位的方案具有如下特点:
1)满足车规、成本低廉,基于摄像头实现而不依靠昂贵传感器,更符合市场需求;
2)在卫星定位信号较差的位置仍可正常工作,例如穿行在城市高楼间或在高架下、隧道内时;
3)摄像头自身捕捉信息丰富,可以借助强大的感知能力最大化地获取车辆环境信息。
因此视觉定位作为自动驾驶中的一项核心技术,已经应用到包括自主泊车在内的多类场景中。
02 传统视觉定位的思考
早在2011年开始的欧盟项目V-Charge1,就是一项基于视觉定位的具有完整代客泊车理念的AVP项目。它基于传统的SFM框架离线构建视觉特征地图,当车辆再次来到停车场时可以通过匹配地图上的特征点,实时估计车辆位姿实现定位。
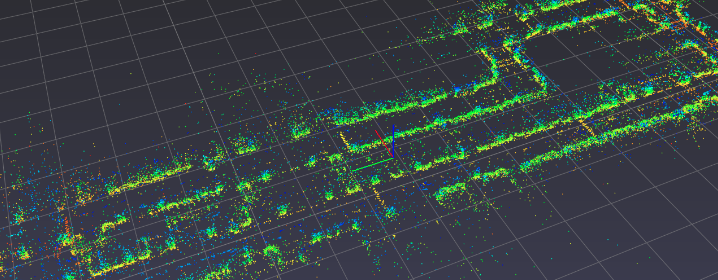
(图1:视觉特征点地图)
不过基于传统视觉算法研发的V-Charge,面临着这样的问题:自主泊车要求车辆具有长期定位的能力,例如能在数天乃至数月后在同一地点进行定位,但依靠单一数据集构建的特征地图很难满足要求。
V-Charge的解决方案是:用同一停车场不同时间段的数据集,构建融合成一个视觉信息更加丰富的长期有效的特征地图。但是这并不能从根本上解决长期定位的问题。
这正好引出了视觉定位面临的一些难题:
1)如何让视觉定位前端算法更加鲁棒?前端特征的选取和数据关联一直是视觉定位中的难题,相比之下后端算法已经相对成熟和稳定。
2)如何实现长期有效的定位?Long-term localization与SLAM技术本身的关注点不同,后者更关注前端特征的选取和后端理论框架的搭建,而前者更关心提升定位算法稳定性,特别是长时间跨度下的定位鲁棒性。
而要解决这两个问题,从目前的研究和应用来看,大概有以下的方向:
1)特征点的选取。使用合适的特征点算法,或使用多个数据集用于地图构建;
2)搭建更好的相机系统或者使用新颖的相机模型;
3)应用深度学习提升视觉感知能力,尤其是将视觉前端的鲁棒性做得更好。
03 非深度学习方法的应用
在这三个方向中,特征点的设计以及相机模型和相机系统,都属于非深度学习的方法。
其中,特征点的选取方面的研究开始得最早。不断有研究人员提出更鲁棒的特征点检测方法,来解决环境光线、视角变化、尺度变化对特征点检测和匹配的影响,同时利用多个图像数据集来弥补单一数据集构建地图信息不足的问题。

(图2:多数据集地图特征点的综合与更新)
而相机系统,指的是用多个相机构成的传感器系统。它既可以解决单目相机尺度无法估计的问题,也能提升视觉定位的鲁棒性和精度。
例如某个相机被遮挡或者面对没有纹理的墙壁时,其他相机仍能正常工作,视觉定位就不容易失效。
再就是相机模型,它主要解决传统的相机投影模型在图像处理中存在的局限性。因为传统的Pinhole模型不太适合鱼眼相机,原始图像产生的巨大畸变会影响图像特征的提取,所以有人提出了新颖的相机投影模型。
比如equirectangular projection,cube-map projection和cylinder projection。它们的初衷都是在不丢失信息的前提下尽可能减小图像的畸变。
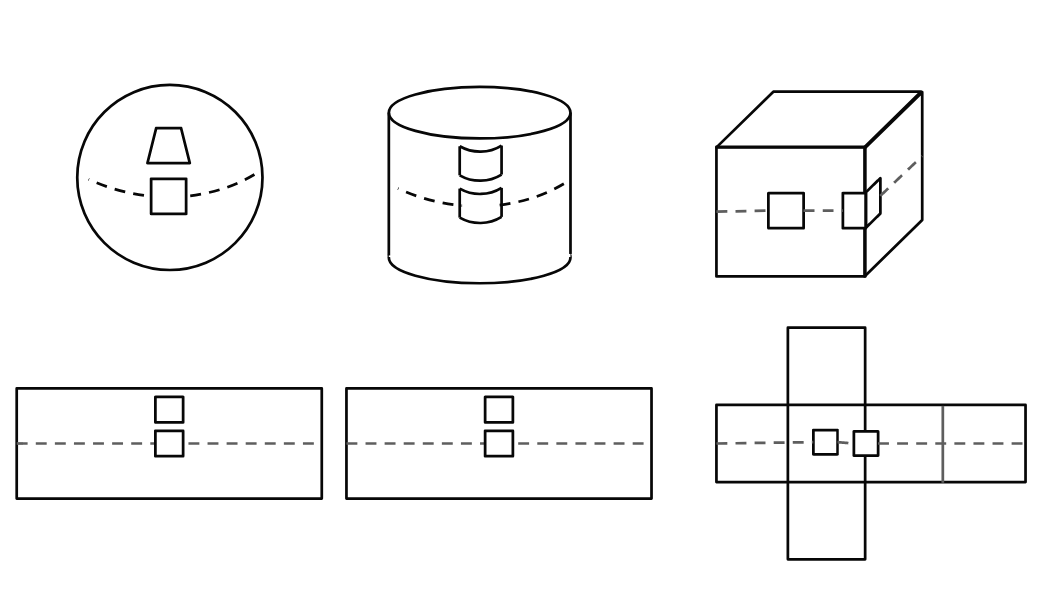
(图3a:不同的相机投影模型 - 投影模型示意图)

(图3b:不同的相机投影模型 - 真实图片投影示例)
通过在特征点的设计和选取上做努力,或者是在相机模型和相机系统上下功夫,都可以一定程度上提升视觉定位的效果。
04 深度学习方法的应用
近几年来深度学习发展迅速,因此也有研究人员将深度学习应用到视觉定位中,进行前端特征的提取。
这些应用大体分为几类:
1)基于深度学习的特征点提取和描述子计算;
2)基于目标检测的视觉定位;
3)基于语义分割的视觉定位;
4)其他的深度学习的定位算法,比如GN-net利用特征图进行位姿计算的方法,或者是其他直接用端到端方式进行定位的方法。

(图4:基于feature points, detections, segmentations的视觉定位方法)
深度学习在图像深层特征提取上具有优势,可以弥补传统视觉算法的不足,利用深度学习改善视觉定位算法的前端,使其鲁棒性得到提升。
Feature Points
其中最直接的想法,就是将深度学习应用在特征点提取上。前两年提出的SuperPoint2是比较典型的代表。
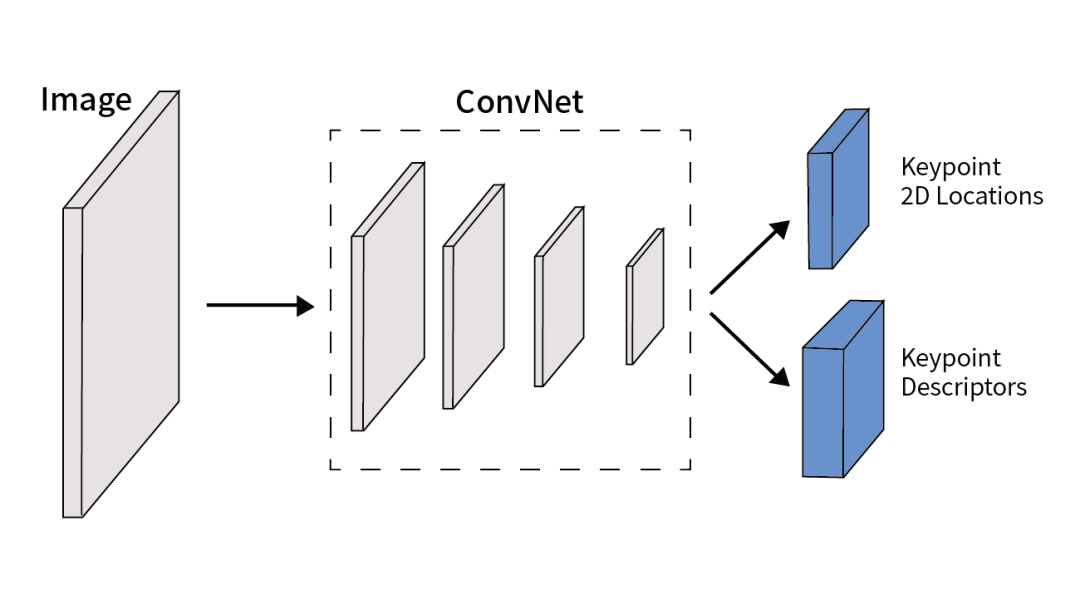
(图5:SuperPoint 网络结构)
虽然真实场景的定位任务面对的环境比较复杂,但通过网络学习的特征点相较于传统的特征点确实更具有鲁棒性。深度学习可以大幅提升特征点检测的性能,在实际的视觉定位中解决不少问题。
Detection
同样的,将目标检测结果应用到视觉定位也是许多人尝试的方向。现有的目标检测技术,特别是2D的目标检测,无论是检测精度还是检出率都能达到很高水平。而其中的重点,就是解决复杂的数据关联问题。
若能很好地解决检测结果的数据关联问题,将目标检测应用到视觉定位上也是一个可行的方向。
Semantic Segmentation
利用语义分割进行视觉定位的方法较为多见,它的一大优势在于:语义分割的结果既能保留图像的几何信息,也能包含简单的类别信息。
比如,将楼房的轮廓结构进行分割,通过分割出的房屋的面和边缘,以及简单几何关系,可以在城市环境中进行定位。或者停车场中,在俯视图上将车位和地面的标识分割出来,就能根据这些信息实现停车场环境下的定位。
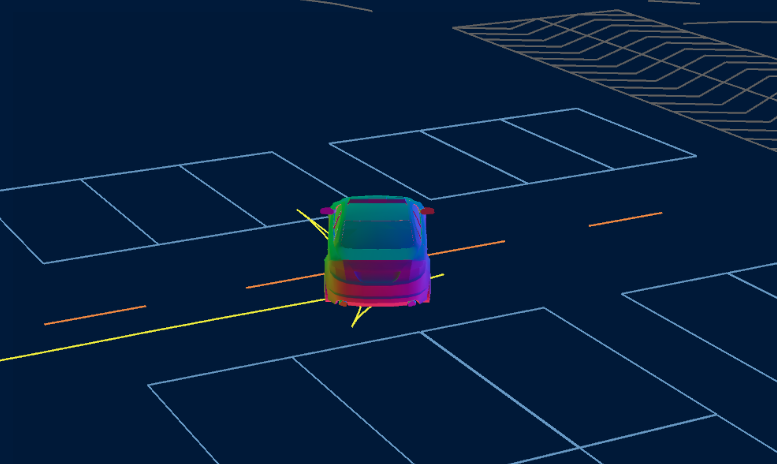
(图6:利用语义分割的视觉定位)
值得一提的是,一套稳定可靠的产品不会只使用一种定位方法,如何将视觉定位与其他定位方法进行有效融合,提升现有方案的定位效果,依然值得继续努力。
相信随着研究的深入,视觉定位方法将在许多自动驾驶的应用中发挥出巨大作用,和其他定位方案一起组成更为鲁棒、精准的定位模块。
References:
[1] Schwesinger U, Bürki M, Timpner J, et al. Automated valet parking and charging for e-mobility[C]//2016 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2016: 157-164.
[2] DeTone D, Malisiewicz T, Rabinovich A. Superpoint: Self-supervised interest point detection and description[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2018: 224-236.
[3] Bowman S L , Atanasov N , Daniilidis K , et al. Probabilistic data association for semantic SLAM[C]// 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017.
[4] Armagan A, Hirzer M, Lepetit V, et al. Semantic segmentation for 3D localization in urban environments[C]. urban remote sensing joint event, 2017: 1-4.
[5] Hu J, Yang M, Xu H, et al. Mapping and Localization using Semantic Road Marking with Centimeter-level Accuracy in Indoor Parking Lots[C]//2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019: 4068-4073.
媒体垂询
media@nullmax.ai相关文章
- Nullmax 2025 年度智权布局回顾,以通用技术智变未来 2026-01-29
- Nullmax VLA 算法深度赋能黑芝麻华山 A2000,释放高阶智驾潜能 2026-01-06
- 普适产品进阶 | Nullmax一体机/小域控的量产加速器 2025-11-26
- 普适产品进阶 | Nullmax 一体机/小域控的“超感视觉” 2025-11-19
- AAAI 2026公布!Nullmax端到端轨迹规划论文入选 2025-11-10
- 上一篇: 泊车不断在升级,以后停车so easy
- 下一篇: 纽劢研习社 | 深度图的「非深度讲解」