IROS 2021分享 | 高精定位如何做到鲁棒又经济?视觉语义+多传感融合可以实现
发布时间:2021-07-07纽劢科技感知组的同学提出了一种基于语义匹配的由粗到精的多传感器融合定位方法,实现了结构化场景下低成本、高精度且鲁棒的自动驾驶定位,近日这项研究已经被IROS 2021收录。IROS全称为IEEE/RSJ International Conference on Intelligent Robots and Systems(智能机器人与系统国际会议),是全球规模最大、影响力最强的机器人研究顶会之一。
在自动驾驶、机器人自主导航等领域,高精度定位扮演着不可或缺的重要角色,但当前的大多数定位方案难以很好地兼顾定位的精度、鲁棒性和成本。在这里,我们将简单地介绍一下这篇文章Coarse-to-fine Semantic Localization with HD Map for Autonomous Driving in Structural Scenes,探讨如何在自动驾驶大规模应用中解决好车辆的“我在哪”问题。
效果视频:
当前的众多定位方案中,GNSS-IMU的惯性导航系统在工业界最为常见,但是很多情况下容易出现卫星信号缺失或者多路径效应的问题。并且受成本影响,高精度的惯性导航系统当前难以大规模商用。
同样,基于激光雷达的定位方案也面临成本高昂的问题,并且大尺度范围内的激光雷达SLAM中,地图存储量巨大,因此实际适用的范围也较为受限。
而视觉传感器感知信息丰富、成本较低,特别是随着近年来深度学习技术的发展,通过图像对环境进行实时、精准的语义感知已经成为现实。
因此,提出了一种应用在结构化场景中,基于高精度矢量地图、以视觉传感器为主的多传感器融合定位方法,应用由粗到精的状态估计范式,通过语义匹配来进行车辆位姿的估计。
整体流程如下:
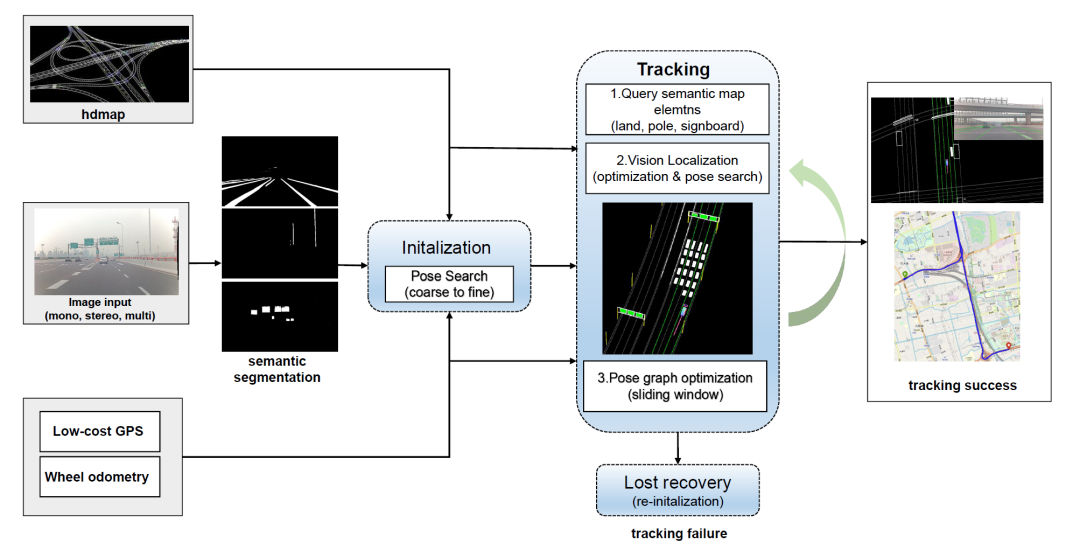
系统输入包含:
- 离线建好的高精地图
- 原始图像(单目、双目或多目图像)
- 消费级的车载GPS以及轮式里程计
主要步骤包括:
1)初始化:基于低精度的GPS测量和语义匹配,进行位姿网格搜索。
2)跟踪:基于高精地图和图像的语义匹配进行位姿优化,通过位姿图优化输出平滑的位姿。
3)丢失恢复:失效检测,计算位姿估计置信度,通过重新初始化来完成系统恢复。

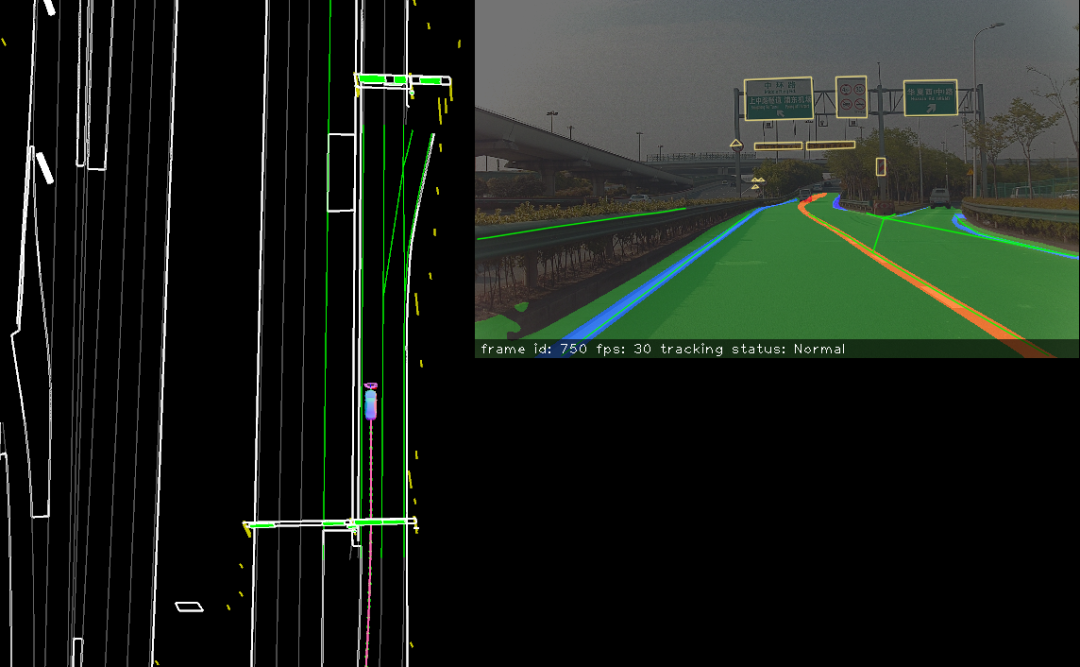
输出的定位结果,即相对于高精地图的位置和姿态,如下所示:
结语:
这是一种低成本、高精度且鲁棒的自动驾驶定位方法,通过融合里程计和车载GPS信息获得鲁棒的定位结果,然后提取图像中稳定的语义特征,进行语义匹配得到车辆位姿的估计。综合来看,非常适合结构化场景下的自动驾驶应用。
PS: 我们正在研发围绕前装量产解决方案的感知技术,包括面向自动驾驶的自车坐标系下三维目标检测及车道线检测,以及基于嵌入式芯片的多任务深度学习基础架构设计。同时我们有很多前沿的视觉感知工作正在进行,包括新一代的感知融合架构、数据成长系统,以及高效稳定的检测、跟踪、建图和定位等技术。
媒体垂询
media@nullmax.ai相关文章
- Nullmax 2025 年度智权布局回顾,以通用技术智变未来 2026-01-29
- Nullmax VLA 算法深度赋能黑芝麻华山 A2000,释放高阶智驾潜能 2026-01-06
- 普适产品进阶 | Nullmax一体机/小域控的量产加速器 2025-11-26
- 普适产品进阶 | Nullmax 一体机/小域控的“超感视觉” 2025-11-19
- AAAI 2026公布!Nullmax端到端轨迹规划论文入选 2025-11-10