One Cycle:数据闭环,走入量产
发布时间:2022-04-19自动驾驶领域,每年都会出现一些热词,数据闭环、数据驱动,就是近两年最受关注的理念之一。因此,行业内出现了某种程度上的“百环齐放、百家争鸣”。
但是,纸面上的数据闭环,和真正走向大规模量产的数据闭环之间,有着不小的距离,能够高效利用海量数据驱动系统成长的闭环方案寥寥无几。完成数据闭环的物理层构建,对于很多企业来说已经是不小的挑战,有能力打造核心的知识层的企业更是少之又少。
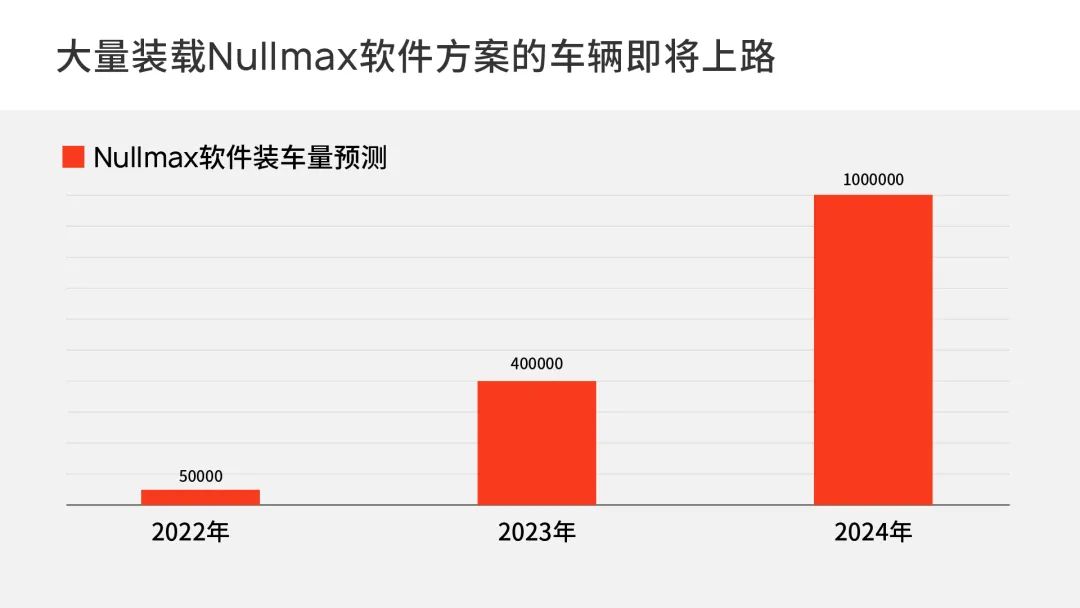
作为一家专注于实现大规模量产应用的自动驾驶公司,Nullmax率先提出了自己的数据成长系统,不仅构建了完善的One Cycle数据闭环,并且正在将它应用到多个车型的量产项目中。
那么,面向大规模量产的数据闭环,到底是一种怎样的存在呢?它和demo项目或者其他简单任务的闭环相比又有什么不同的地方呢?
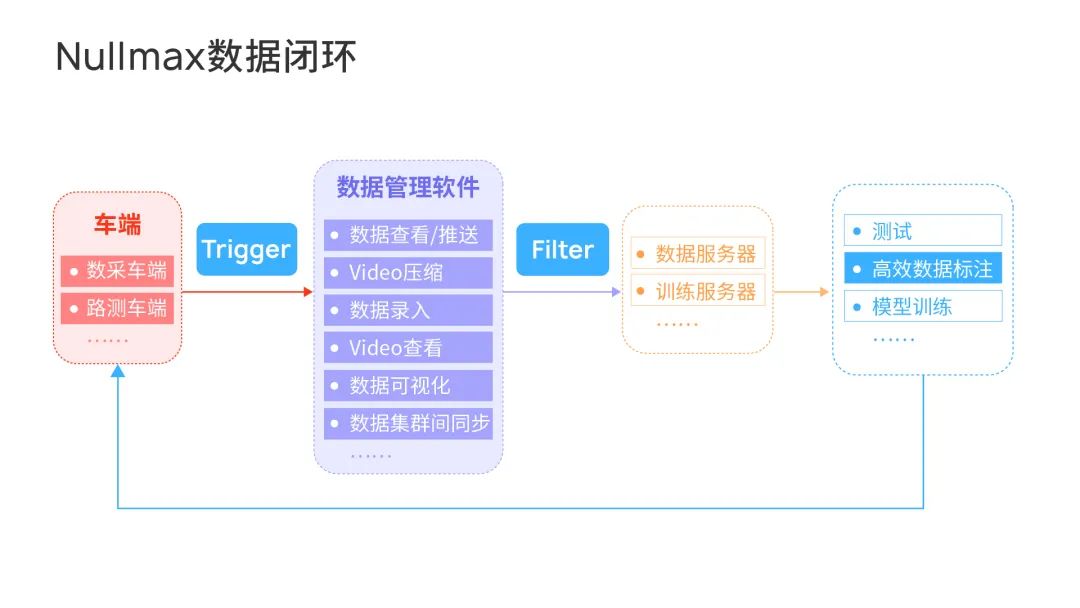
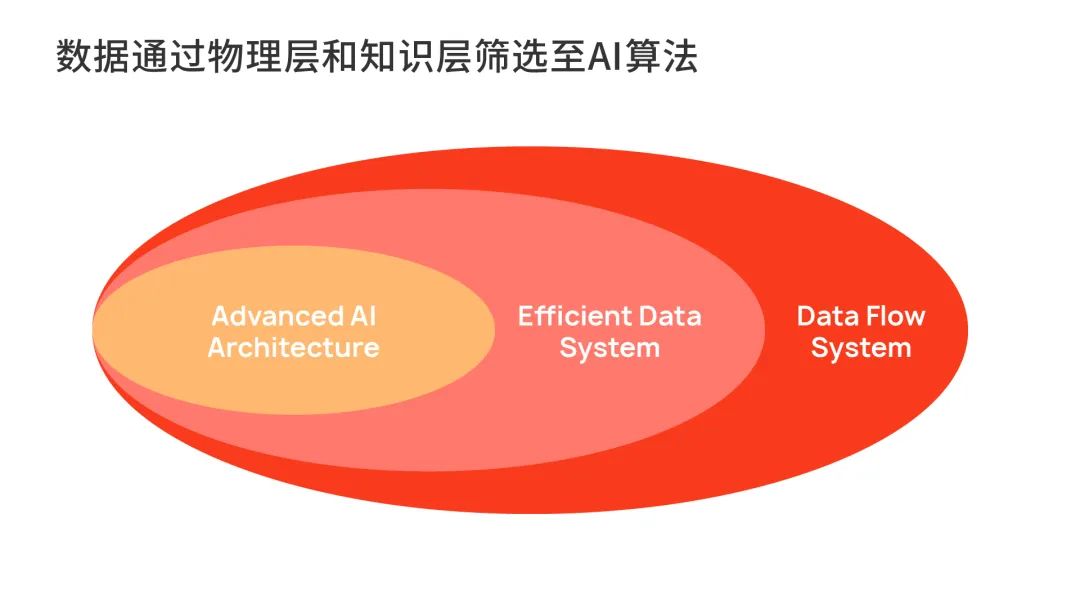
具体而言,One Cycle由两个主要的部分组成,分别是数据物理层Data Flow System和知识层Efficient Data System。前者完成数据的汇入和管理,后者完成有价值数据的筛选,最终为整体的AI算法输入有用的知识。
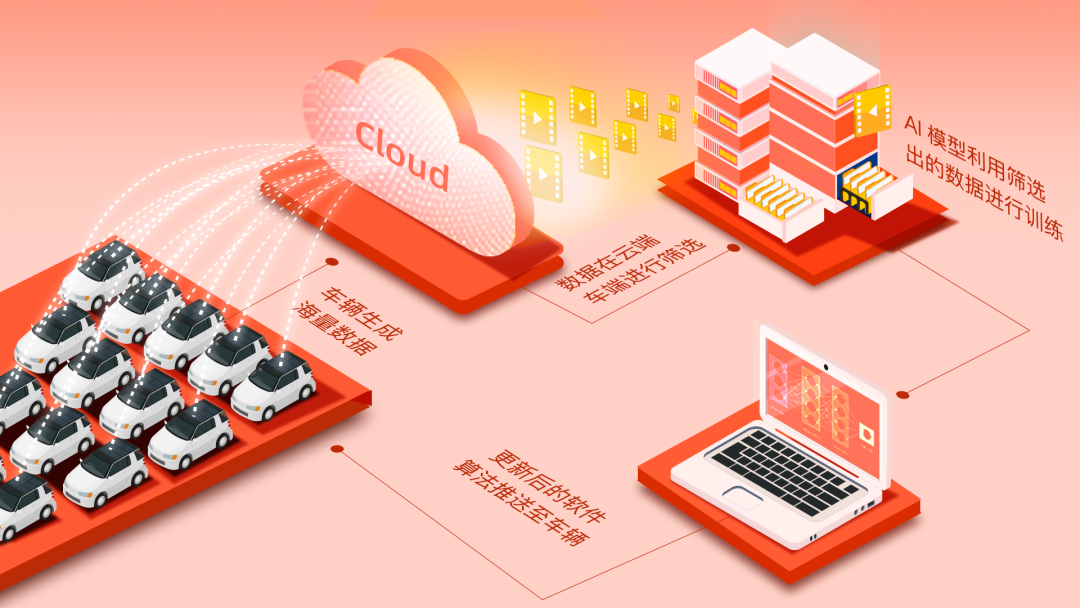
在自动驾驶开发中,海量数据需要从不同的车端,以合适的格式和方式,尽快传到云端,进行高效的存储和数据回放。然后在回放之后,优化的算法再高效地回传到车端。而这,正是Data Flow System的作用。
笼统来看,Data Flow System包含了底层的硬件集群以及软件系统,解决了数据如何传输、压缩、存储、管理等等问题,不涉及到算法。
而在Data Flow System之中,核心部分是数据管理软件,它主要包括了数据的查看和推送,视频压缩和数据录入,视频查看,数据可视化,以及数据集群间的同步,等等。
比如,系统在接收数据时,对于数据占用量庞大的海量图片,就会通过视频压缩后录入;而其他传感器的数据,也会以定义的压缩格式进行录入。
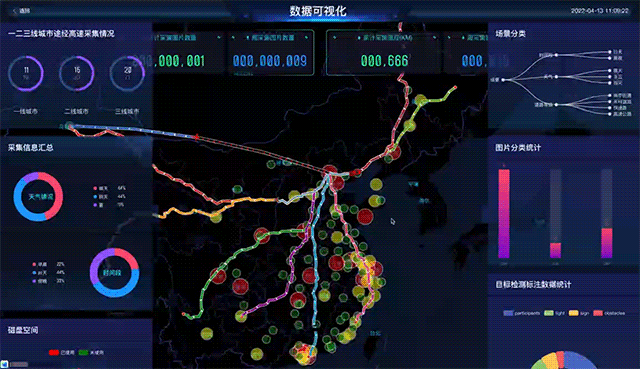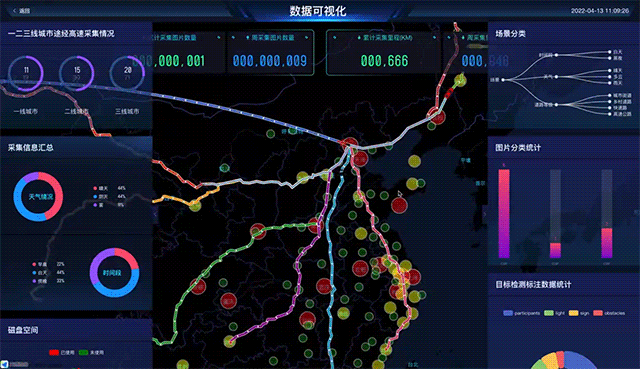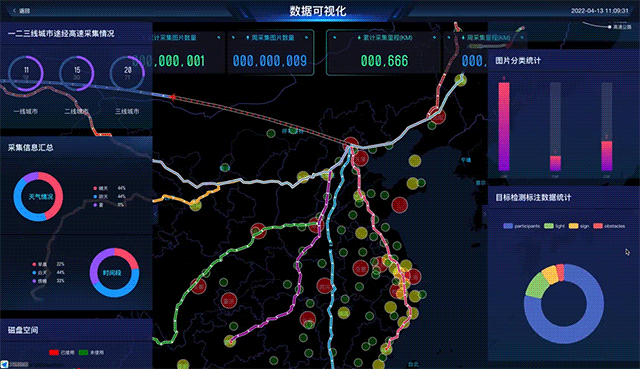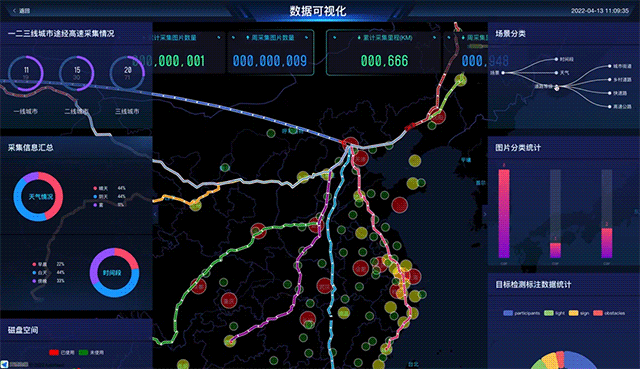
数据录入之后,数据管理软件就能够提供相应的可视化。比如,工程师可以直接在地图上看到全国的覆盖情况,也可以直接从第一人称视角回放当时的数据。

大家熟知的影子模式,就是人机不一致性的触发方式,它将司机行为和自动驾驶行为进行比较。比如,系统认为需要加速但驾驶员踩了刹车,那么就会触发对应的Trigger进行数据收集。
同时,Trigger也设置了不同的分类和优先级,等级越高的情况,数据记录的时间也会越长。
在此之外,部署在云端的Filter也会筛选有价值数据,分析数据采集车辆输入的数据。Filter的方式同样也有很多种,目的就是找到这些数据相对于AI模型的不确定性,从而挖掘出新的知识。

比如,在云端使用性能更强的模型和车端的模型进行比较,又或是通过相关性比较弱的多种模型交叉检验,如果输出结果不一致,那就说明其中蕴含有新的知识。
Filter有两个重要的衡量指标:召回率,准确率。召回率代表着这个知识过滤体系找出问题数据的能力,准确率则代表的是“一找一个准”的能力。
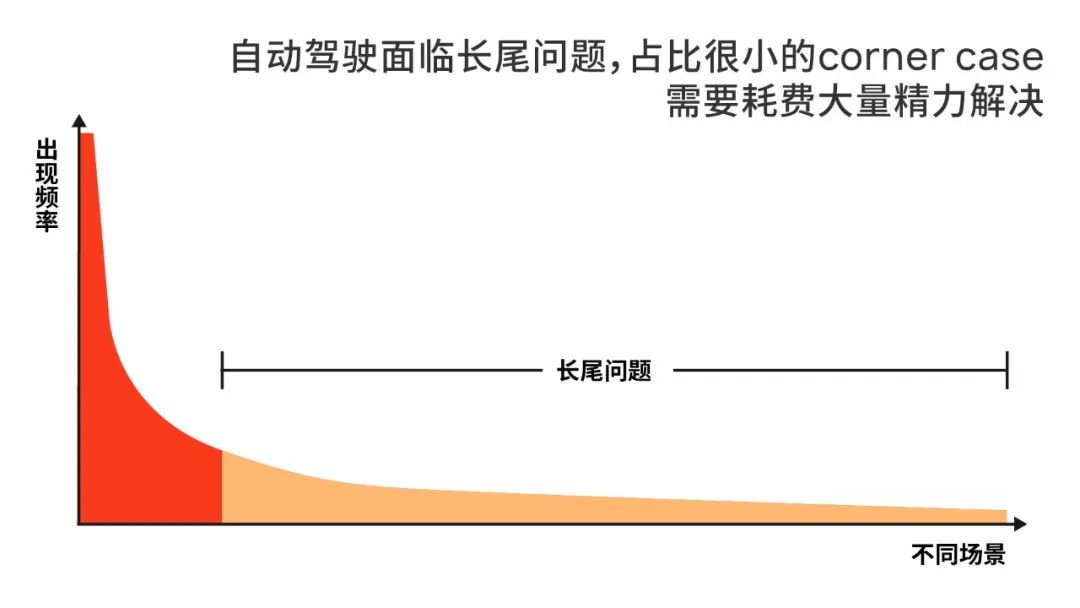
知识层的长期目标,是在保持一定准确率的情况下,持续地提高召回率。因为整体而言,问题数据相对很少,召回率的提升是主要问题,一定范围内的误召回不会给整体成本带来太大影响。
而在Trigger 和 Filter 以外,另外一点非常重要的就是高效的标注工具。在发掘出有价值的数据出后,Nullmax的标注工具只对数据进行增量标注,通过神经网络预先找出数据中的问题部分进行标注和学习,而不是将任务目标全部标注一遍。不仅标注效率更高,而且标注成本也显著降低。
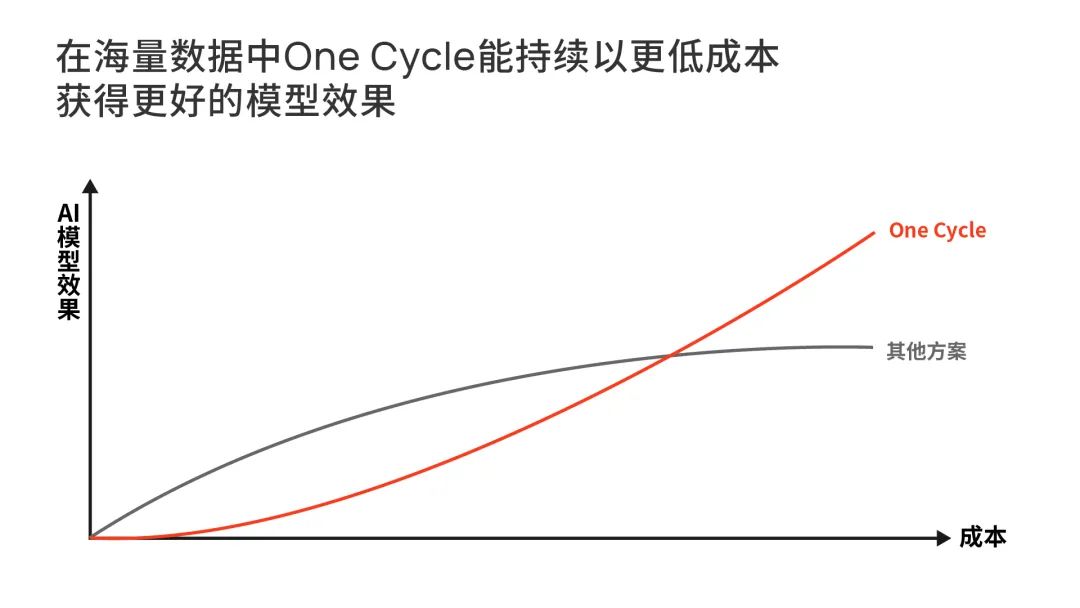
知识层的整体存在,让系统做到了高效且低成本地挖掘知识,在数据量快速上升的未来,这是 AI 竞争的关键所在。
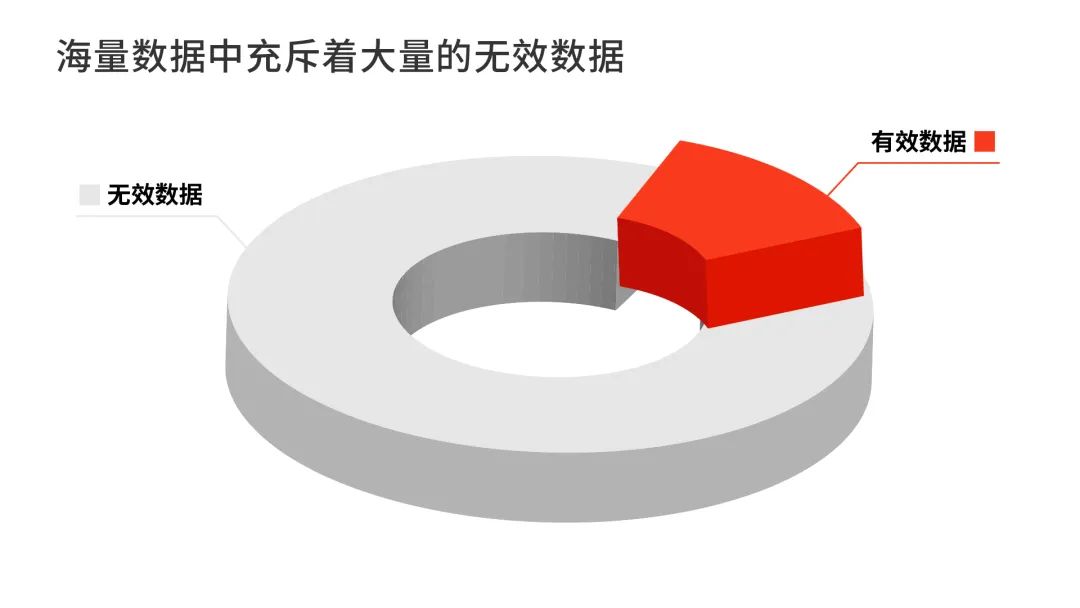
至此,数据闭环才能全力发挥作用,而不会被茫茫数据淹没,又或者是一无所获。构建这样的平台体系是一项巨大的挑战,当中很容易陷入小作坊式的数据闭环。
小作坊式的特征,是没有高效的数据回传和过滤,绝大部分时候依赖工程师去发现问题,效率很低。它只能应对demo级的功能以及一些固定的路线、区域的复杂任务,又或者是场景很少的简单量产任务。
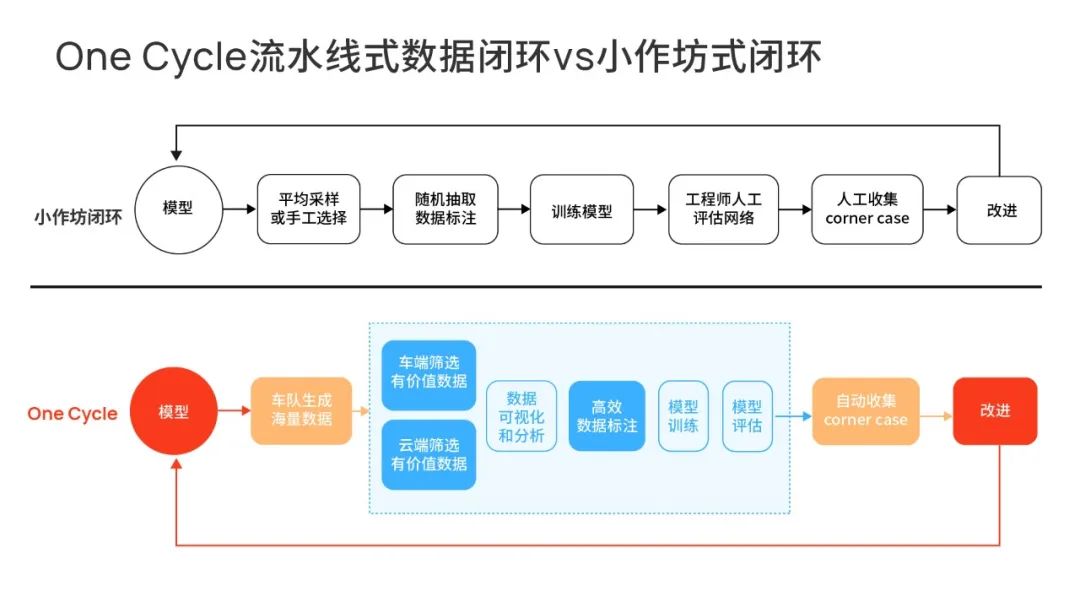
当面对的是场景层出不穷,数据海量涌来的真实量产应用,那么小作坊式的数据闭环就会没有招架之力。
因为对于复杂的自动驾驶来说,它需要的一定是高度自动化的流水线式数据闭环,所以高效的数据物理层、知识层缺一不可。
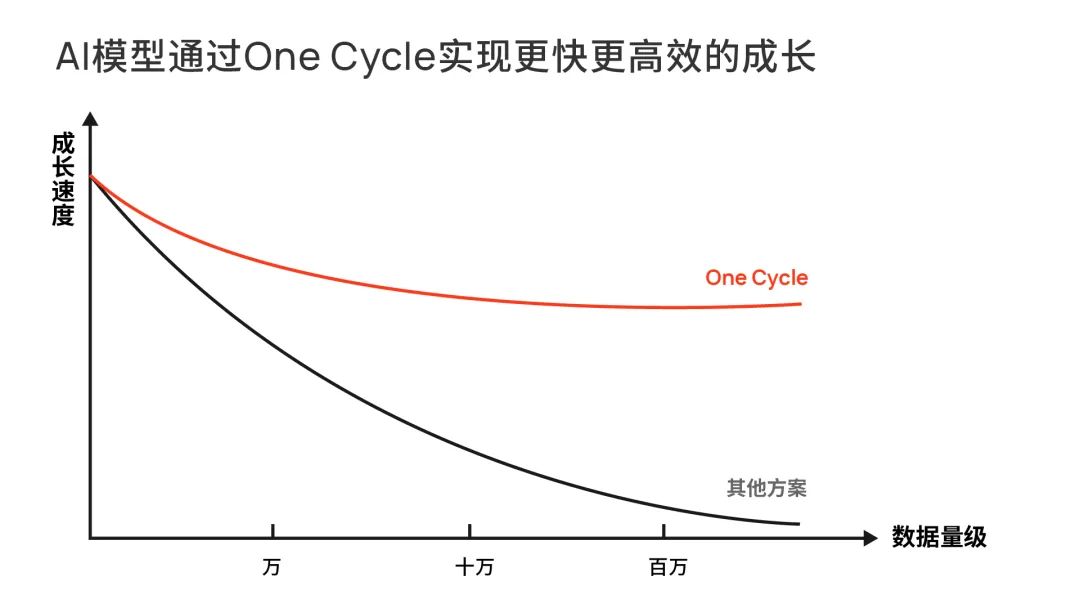
在这样的数据平台下,先进的AI架构,将被数据喂养得越来越健壮,快速成长,最终形成一个足够强大的神经网络架构,学得自动驾驶所需的所有知识。
媒体垂询
media@nullmax.ai相关文章
- Nullmax进化学 |「纯视觉」眼中的世界,有亿点点震撼 2024-08-26
- Nullmax论文入选ECCV 2024!新方法SimPB实现多相机BEV和图像空间同时检测 2024-07-08
- 走进 Nullmax 感知测试:真会「找茬儿」,真有技术! 2024-06-05
- 高效交付有章法,Nullmax量产工程深度解析 2024-04-19
- 打造智驾「新质生产力」,Nullmax BEV-AI技术架构带飞上分! 2024-03-28