从3D车道线到局部地图,BEV视角求解「路在何方」| Nullmax进化学
发布时间:2023-02-17BEV感知与车道线检测
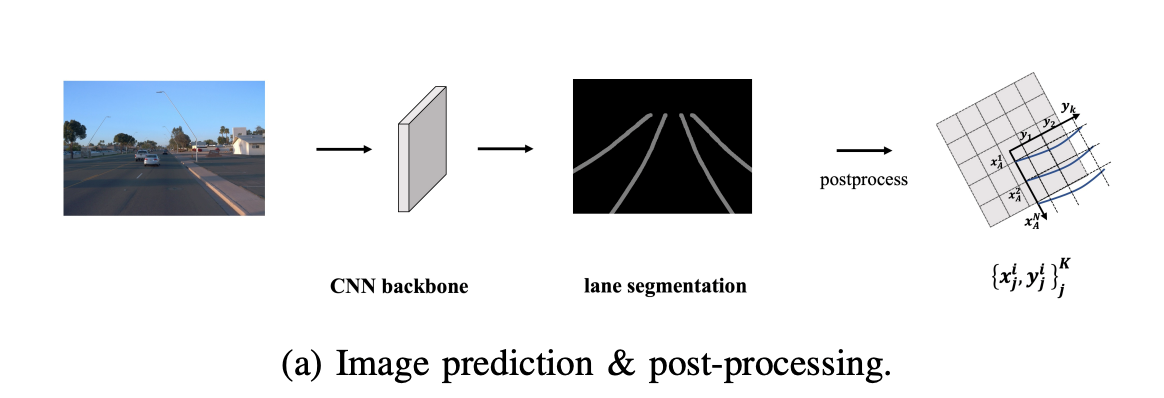
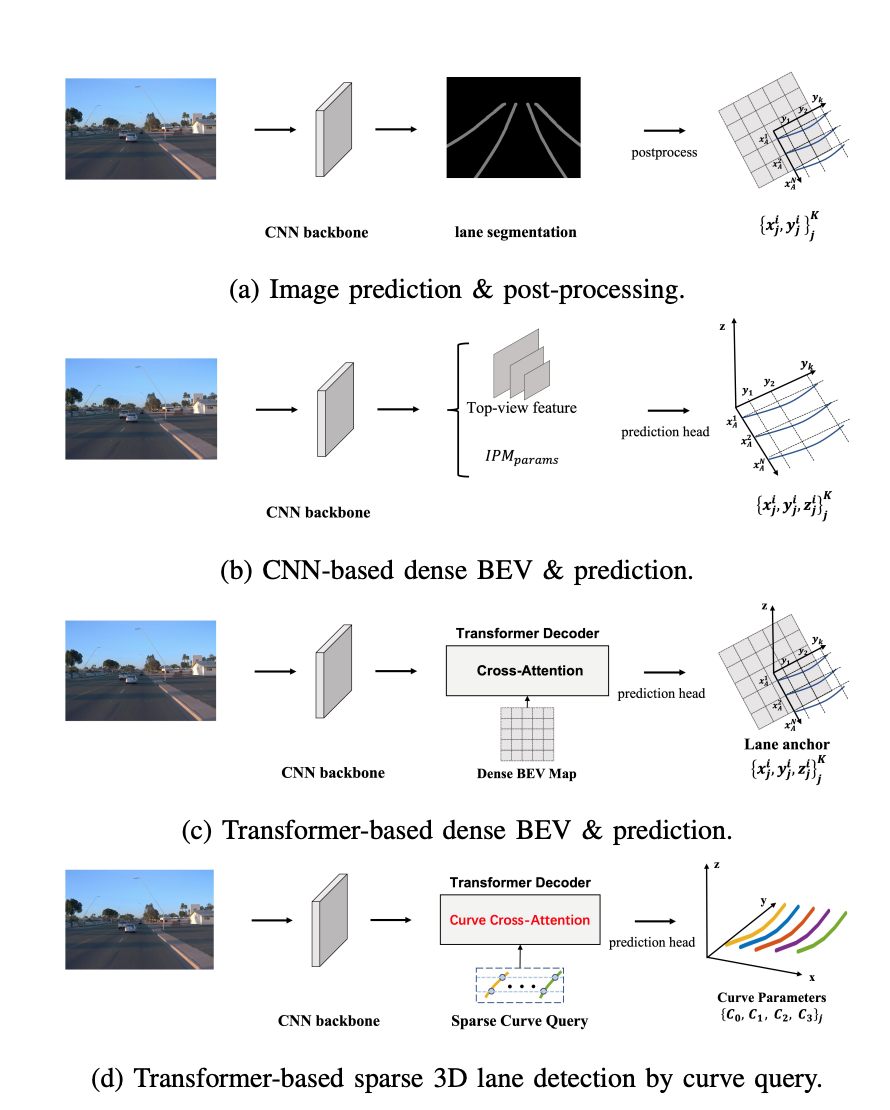
面向量产的3D车道线算法
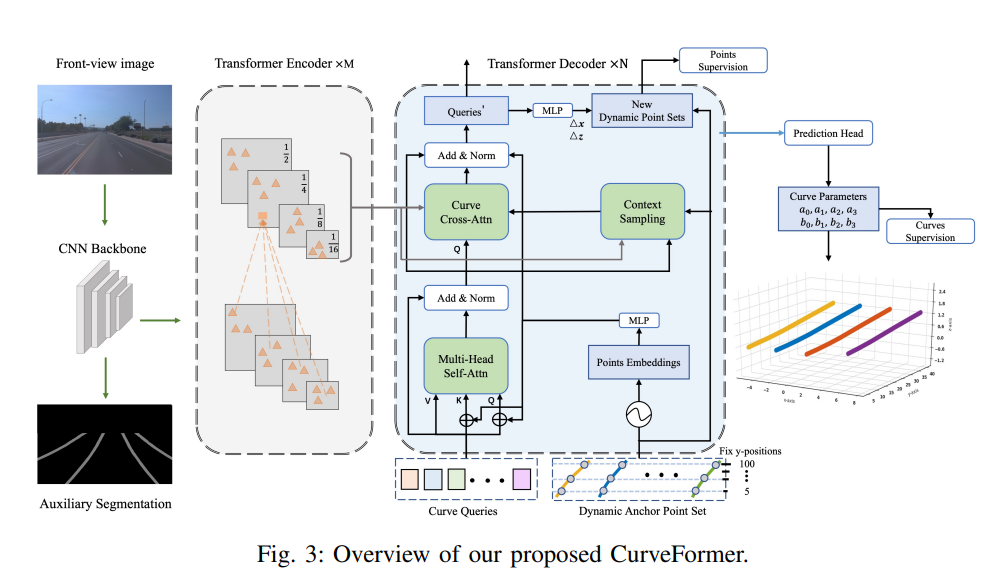 在合成数据集和真实世界数据集上,CurveFormer与3D-LaneNet、Gen-LaneNet、PersFormer等优秀算法进行了对比,实验数据显示CurveFormer拥有非常全面的优异性能,优于其他算法。因此在量产应用中,CurveFormer也呈现出了巨大的落地优势,不仅任务效果出众,可以满足复杂城市道路等场景下的车道线检测要求,而且计算需求不大,可以部署到算力较低的量产计算平台之上。
在合成数据集和真实世界数据集上,CurveFormer与3D-LaneNet、Gen-LaneNet、PersFormer等优秀算法进行了对比,实验数据显示CurveFormer拥有非常全面的优异性能,优于其他算法。因此在量产应用中,CurveFormer也呈现出了巨大的落地优势,不仅任务效果出众,可以满足复杂城市道路等场景下的车道线检测要求,而且计算需求不大,可以部署到算力较低的量产计算平台之上。局部地图与全场景驾驶
局部地图和其他地图相比,不仅关注地图信息的高精度,还尤为看重车端的实时性,因此这也对算法提出了很高的要求。
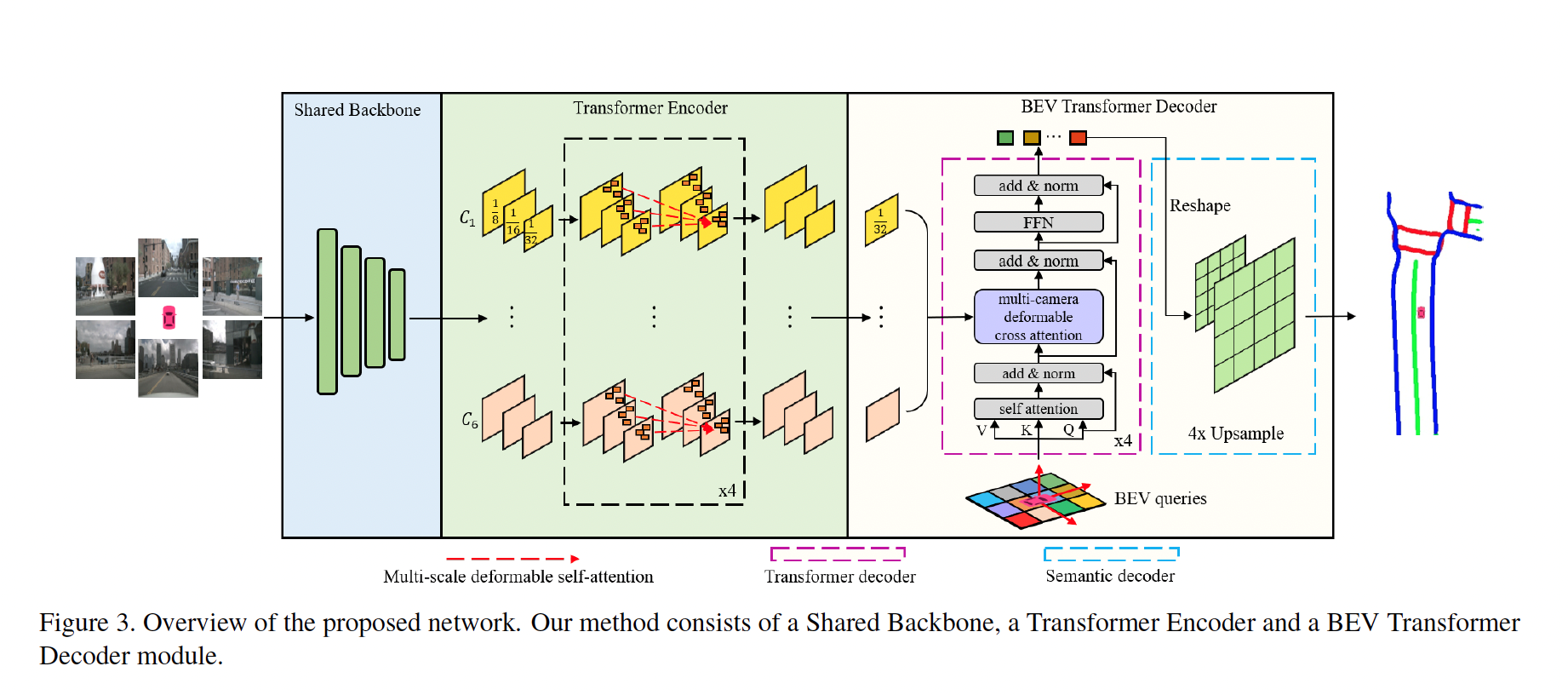
卓越的BEV语义分割
这一基于Transformer的BEV语义分割方法,同样也取得了当下业界最优(SOTA)的算法效果,论文入选计算机视觉学术会议WACV 2023。BEVSegFormer相比于HDMapNet等优秀算法,性能提升超过了10个百分点。
结语
媒体垂询
media@nullmax.ai相关文章
- Nullmax进化学 |「纯视觉」眼中的世界,有亿点点震撼 2024-08-26
- Nullmax论文入选ECCV 2024!新方法SimPB实现多相机BEV和图像空间同时检测 2024-07-08
- 走进 Nullmax 感知测试:真会「找茬儿」,真有技术! 2024-06-05
- 高效交付有章法,Nullmax量产工程深度解析 2024-04-19
- 打造智驾「新质生产力」,Nullmax BEV-AI技术架构带飞上分! 2024-03-28