Nullmax进化学 |「纯视觉」眼中的世界,有亿点点震撼
发布时间:2024-08-26一直以来,像人类一样开车都被看作是自动驾驶技术发展的绝佳方向,由于视觉可以获取极为丰富的环境信息, 因此“纯视觉”技术也被看作是自动驾驶乃至新一代机器人的核心能力。
通过AI和摄像头,机器可以像人类一样识别画面中的颜色、形状、纹理、空间关系信息,准确理解周围的世界。比如,自动驾驶的汽车通过视觉识别两旁的路沿、栅栏,区分不同颜色、类型的车道线,检测行人、汽车、锥桶、水马、交通标志等等,而且可以直接输出驾驶的行为。
这些数以百万、数以千万的彩色像素与AI模型的结合,为自动驾驶带来了无限可能,尤其是纯视觉呈现的出色理解、交互能力,更不只是一点点震撼!
纯视觉「拿捏」全场景智驾
纯视觉的自动驾驶,通过AI看到的会是一个怎样的世界呢?这是Nullmax的7V纯视觉车辆,从一条道路转入另一条道路时,端到端自动驾驶模型输出的可视化信息。
画面中,自车从左侧的车道向前行驶,在识别出路口前新增的左转车道之后,向左完成变道,然后进入路口。同时,对向车道有一连串车辆正在右转进入相同目标车道。自车在合适时机平滑汇入车流中,驶入正确车道,并绕过压线停在路边的大巴,之后等待路边驶出的掉头车辆,最后完成整个转弯过程。
当中,红色的点描绘出了栅栏、路沿这些道路的边界,蓝色、绿色描绘了路面车道的实线、虚线情况,天蓝色代表停止线,黄色的线则是模型规划出的自车行驶轨迹。而大小各异、颜色不同的方框中,红色代表了小型汽车,天蓝色是电瓶车、摩托车,紫色框代表自行车,黄色框是行人,绿色的是大型车辆。
这些看似简单的点、线、框,展示了Nullmax端到端自动驾驶模型出色的场景理解能力,尤其是对于复杂道路结构的理解能力。这样,无需任何地图提供道路属性和拓扑关系,车端通过纯视觉的AI推理就可以实时获取所需的环境信息,实现真正“有路就能开”的全场景智驾,而且能够应用到全球范围,不受国家和地区限制。
端到端塑造智驾「黑神话」
Nullmax的端到端自动驾驶模型,将视觉信息作为主要输入,车辆只用配备基础的摄像头,根据导航系统提供的左右转等指令,就可以实现城市场景的点到点智能驾驶。
当中,端到端模型就像人类的大脑一样,基于视觉信号的输入,就可以完成对场景的理解和行为的规划,包括动态、静态的感知任务,并且能够一步到位直接输出驾驶行为。比如,在路口一分二车道情形下变入正确的车道,在两侧都有栅栏的狭窄操作空间完成转弯,灵活地与障碍物交互,等等。
而且由于传感器配置简单,所以整体算力需求也相对更低,Nullmax的技术方案可以在100T稀疏算力内实现城市场景的领航功能。即便是价位相对便宜的车型,哪怕没有配备昂贵的传感器和超大算力的芯片,也可以享受到安全、智能的体验。
端到端模型曾被不少人看作是黑盒子,因为输出的结果缺乏解释性,但是通过多模态的输出,其实可以解释端到端模型的结果。比如Nullmax的端到端模型可以同时输出动态感知、静态感知、场景描述、驾驶行为,这些不同模态的信息就可以很好地解释模型输出的结果。
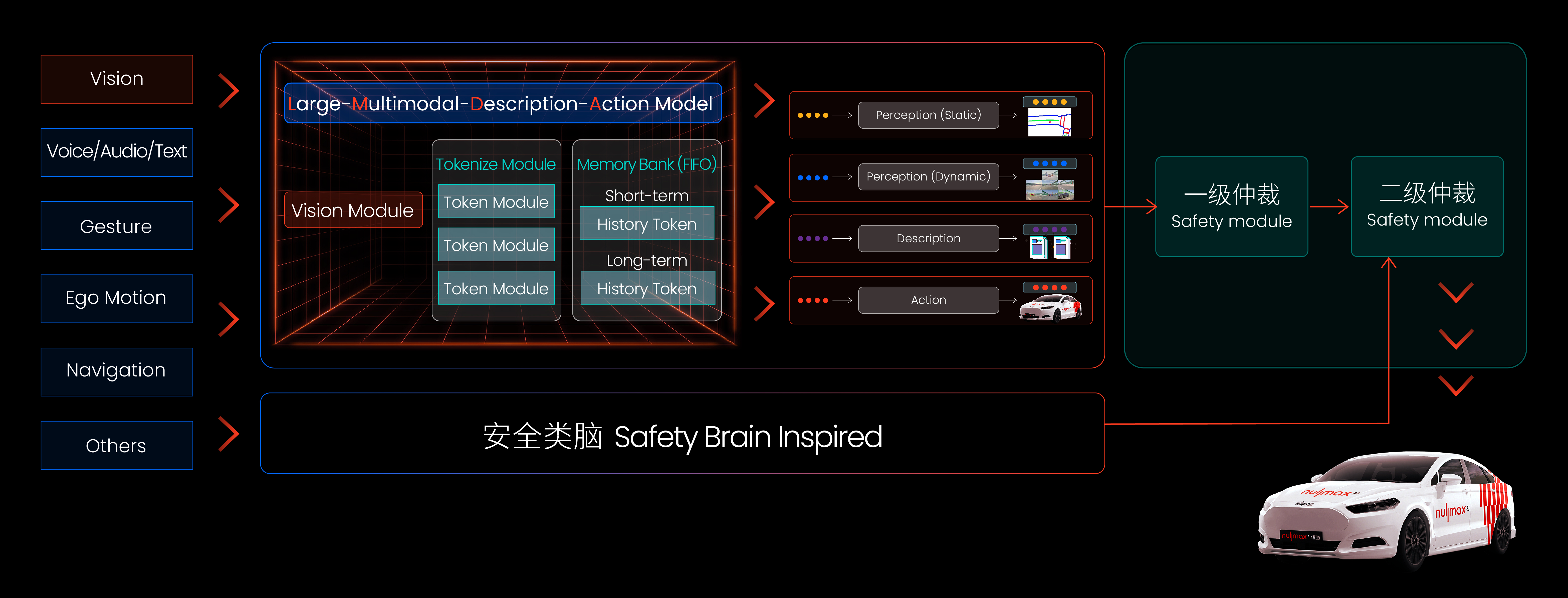
事实上,由于端到端自动驾驶模型的出色效果和巨大潜力,过去的“黑盒子”俨然已成为“黑神话”,正在塑造新一代的自动驾驶。
顶会论文「硬控」纯视觉
对于人类司机而言,开车首要的是“看路”,自动驾驶也一样,这样才能通过车道内的行驶、车道间的变换以及不同道路之间的衔接转换,实现从起点到终点的连贯体验。
这种“看路”的本领,包括了复杂道路结构的理解能力和常规车道的识别能力。在2022年,Nullmax先后发表了适用于任意相机配置的实时生成局部地图方法BEVSegFormer,以及不显式构建BEV的高效3D车道线检测方法CurveFormer,并被WACV和ICRA两项国际学术会议收录。
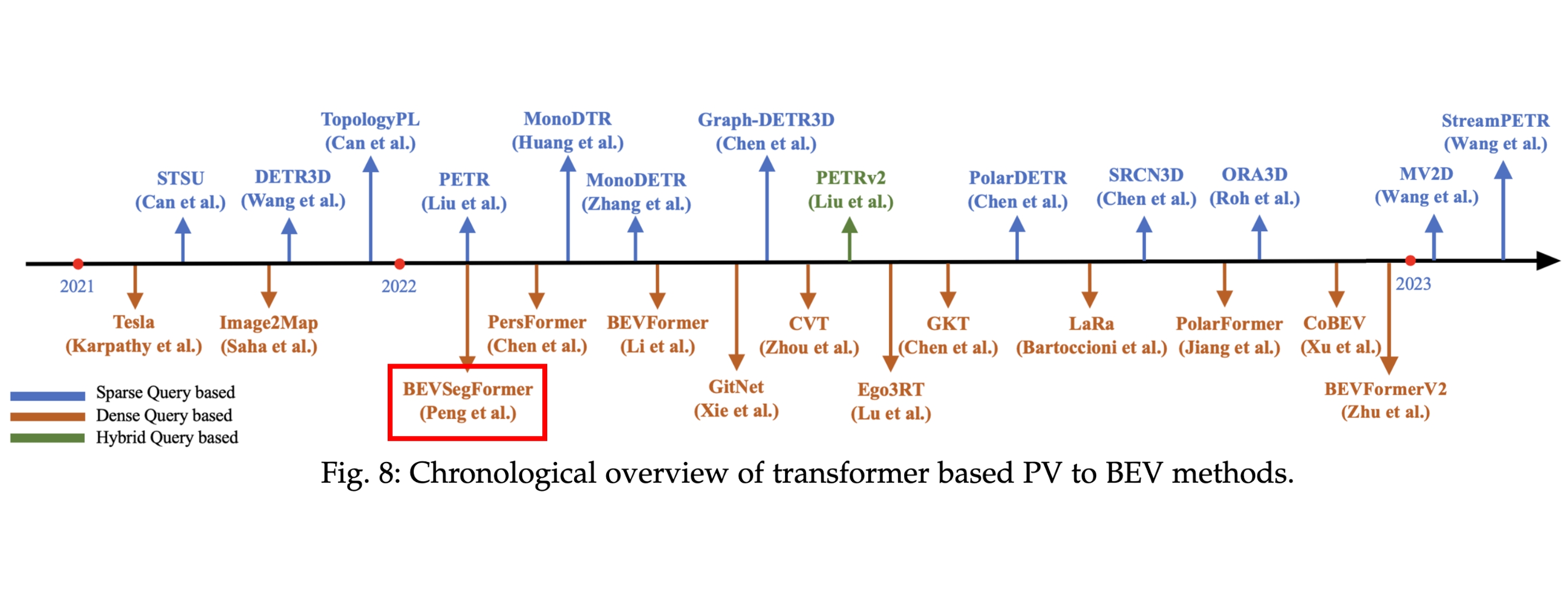
根据计算机视觉领域最顶级期刊IEEE TPAMI的综述论文《Vision-Centric BEV Perception: A Survey》的梳理,Nullmax提出的BEVSegFormer是BEV感知方面国内最早公开发表的一项代表性研究。
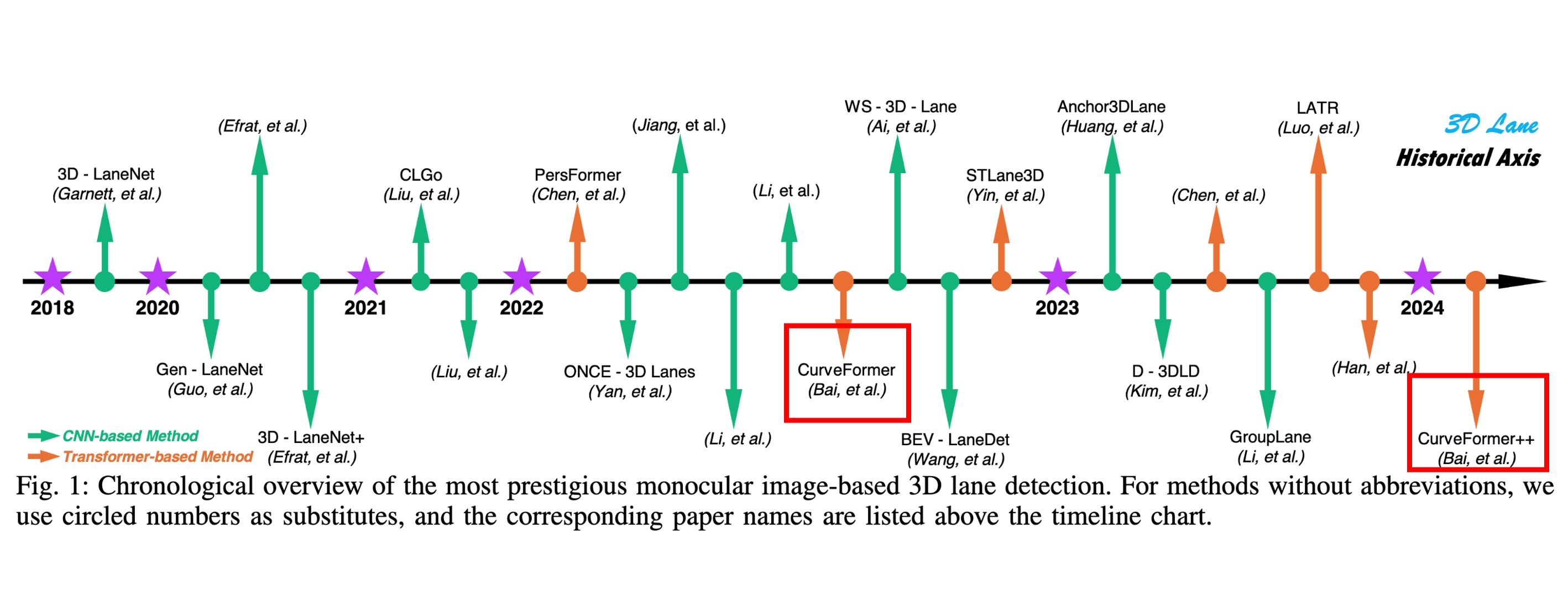
在单目3D车道线检测方面,根据另一篇综述论文《Monocular 3D lane detection for Autonomous Driving: Recent Achievements, Challenges, and Outlooks》的汇总,Nullmax的CurveFormer同样是领域内最早的开创性工作之一,升级之作CurveFormer++也是今年极具影响力的研究之一。
正是通过将这些优秀的算法设计整合到端到端自动驾驶模型中,Nullmax的纯视觉车辆可以在没有任何地图信息的情况下,通过摄像头实时理解各种场景下的道路结构。
除了“看路”之外,在今年的国际计算机视觉顶级会议CVPR和ECCV上,Nullmax有两篇纯视觉的目标检测研究被收录,一篇是利用2D检测增强3D目标检测的方法QAF2D,另一篇是多相机同时进行2D和3D检测的方法SimPB。通过将图像空间和BEV空间的不同检测优势紧密结合,Nullmax让纯视觉的障碍物检测看得更远、更准,而且非常稳定。
在纯视觉感知环境信息的基础上,Nullmax还探索了进一步融合时序信息,让自动驾驶的静态感知、动态感知和规划像人类一样拥有“记忆”。Nullmax在今年2月份提出的升级算法CurveFormer++,正是探索了稀疏Query时序融合方式,比较了四种不同的时序融合方式。
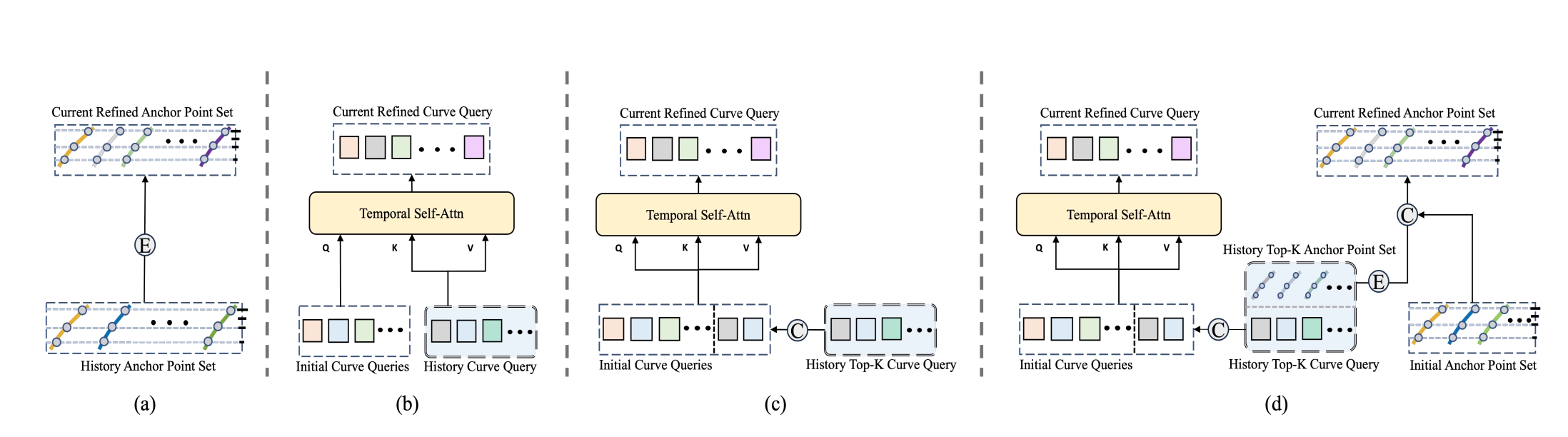
对于自动驾驶而言,如果记忆的信息过多,硬件难以存下或者运行很慢;存的信息过少,效果提升则不明显,因此到底利用哪些时序信息也就成了关键。Nullmax提出的稀疏Query时序融合方案,既保证了时序信息高效应用到AI模型当中,取得很好的效果,又不需要消耗过多计算资源。
正是源自这些长期以来的纯视觉研究,Nullmax在端到端自动驾驶开发以及纯视觉智驾方案落地上,拥有了独特的技术优势。
结语
Nullmax坚信,纯视觉对于自动驾驶而言是一项必备、核心的技术能力,它不仅可以独立实现各种各样的任务和功能,而且也是通向无人驾驶、具身智能的关键。顶尖的纯视觉技术可以实现更广泛的普及应用,也可以开启更高的智能上限。
媒体垂询
media@nullmax.ai相关文章
- Nullmax 2025 年度智权布局回顾,以通用技术智变未来 2026-01-29
- 普适产品进阶 | Nullmax一体机/小域控的量产加速器 2025-11-26
- 普适产品进阶 | Nullmax 一体机/小域控的“超感视觉” 2025-11-19
- AAAI 2026公布!Nullmax端到端轨迹规划论文入选 2025-11-10
- 直面刚需场景,Nullmax 高通48TOPS 舱驾一体方案完成实车部署 2025-09-29